本文最后更新于:2022年11月4日 凌晨
排序都要做的事情是比较和交换
稳定排序:排序前后,两个相等的元素在其序列中的前后位置顺序相同
这里只有插入排序和归并排序是稳定排序
以下示例均假设我们要从小到大进行排序
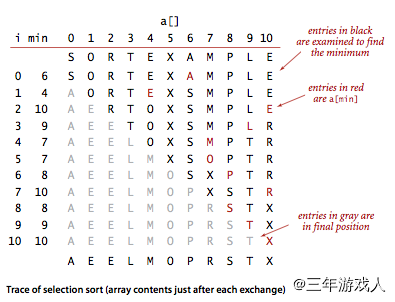
选择排序
非稳定排序
排序效率和输入无关
选择排序的基本步骤:先找出最小元素放到0号位置,再找出次小元素放到1号位置,再找出次次小元素放到2号位置,以此类推
排序过程中的数据变化
排序过程图形化
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 #ifndef __SELECTIONSORT_H__ #define __SELECTIONSORT_H__ class Selection public :void Sort(char *a, int length)for (int index = 0 ; index < length - 1 ; ++index )int indexOfCurMin = index ;for (int i = index + 1 ; i < length; ++i)if (a[i] < a[indexOfCurMin])int temp = a[index ];index ] = a[indexOfCurMin];#endif
特性
该算法的优点是对输入数据的移动次数最少。缺点是运行效率低,无法处理大规模的数据
## 性能分析 使用该算法对n个元素进行排序时
时间复杂度为O(n^2),需要对元素进行n(n-1)/2次比较以及n-1次交换。值得注意的是,元素交换次数与元素个数成线性关系,这是其它排序算法都没有的
空间复杂度为0
插入排序
稳定排序
排序效率和输入有关,当待排序的元素越有序(倒置很少)时,该算法可能比其它任何算法都要快
插入排序的基本步骤:每一次都将一个未排序的元素插入到已经排好序的数组中
排序过程中的数据变化
排序过程图形化
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #ifndef __INSERTIONSOER_H__ #define __INSERTIONSOER_H__ class Insertion public :void Sort1_0(char *a, int length)for (int index = 1 ; index < length; ++index )for (int i = index ; i > 0 ; --i)if (a[i] < a[i - 1 ])char temp = a[i];1 ];1 ] = temp;void Sort2_0(char *a, int length)for (int index = 1 ; index < length; ++index )char needToInsert = a[index ];int i;for (i = index - 1 ; i >= 0 && needToInsert < a[i]; --i)1 ] = a[i]; 1 ] = needToInsert;#endif
特性
这里需要补充两个概念
倒置:两个待排序元素的排列顺序与目标顺序相反
部分有序:如果元素倒置的数量小于元素个数的某个倍数时,那么就说这些待排序元素是部分有序的
该算法缺点是运行效率低,无法处理大规模的数据
插入排序和冒泡排序很像,冒泡排序的算法如下:从未排序元素的第一对直到最后一对,如果第一个元素比第二个元素大就交换,重复这个步骤直到所有元素都排序完成
性能分析
使用该算法对n个元素进行排序时
时间复杂度在最坏的情况下为O(n2),最好的情况为O(n),所以平均为O(n 2)。元素间的比较次数大于等于倒置数,小于等于倒置数+数组大小-1,在最坏的情况下为n(n-1)/2次,最好的情况下为n-1次。元素间进行交换的次数等于倒置数,在最坏的情况下为n(n-1)/2次,最好的情况下为0次
空间复杂度为0
希尔排序
非稳定排序
排序效率是否输入有关取决于第二步使用的排序算法是否输入有关
希尔排序的基本步骤: 1. 确定h的初值 1.
每次循环都使数组中任意间隔为h的元素都是有序的(这样的数组称为h有序数组)
1. 每次循环结束,h都要递减一次,直到h等于1
ps:h的递减方式是多种多样的,不同的递减方式决定了希尔排序算法的效率,目前还没有研究出最好的递减序列
递减序列的一个例子
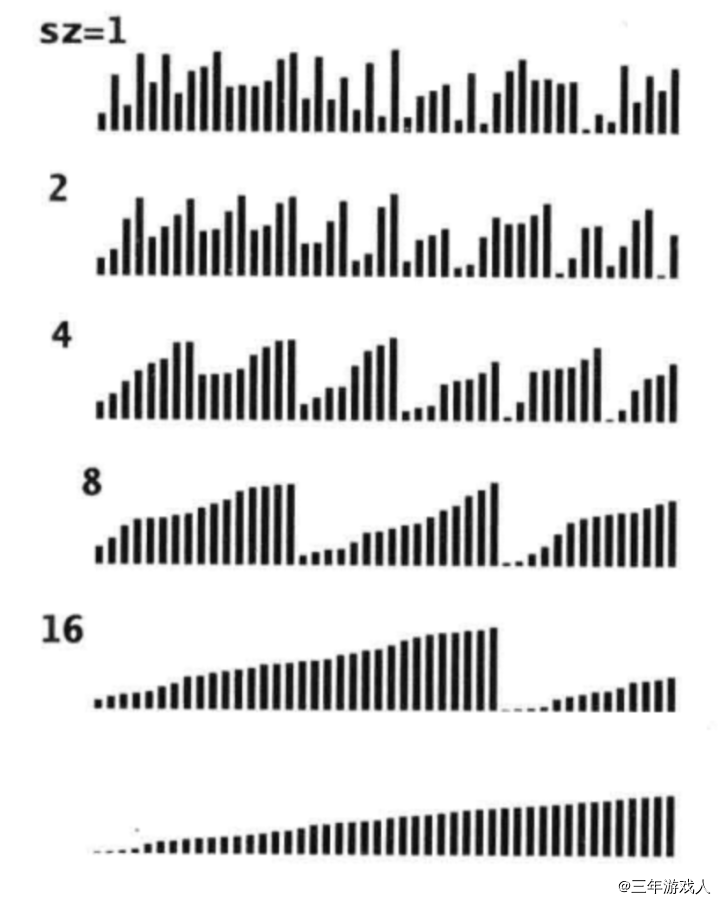
排序过程图形化
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 #ifndef __SHELLSORT_H__ #define __SHELLSORT_H__ class Shell public :void Sort1_0 (char *a, int length) {int h = 1 ;while (h < length / 3 )3 * h + 1 ; while (h >= 1 ) for (int i = 0 ; i < h; ++i) for (int j = i + h; j < length; j += h)char needToInsert = a[j];int k;for (k = j - h; j >= i&&needToInsert < a[k]; k -= h)3 ;void Sort2_0 (char *a, int length) {int h = 1 ;while (h < length / 3 )3 * h + 1 ; while (h >= 1 )for (int i = h; i < length; ++i) char needToInsert = a[i];int j;for (j = i - h; j >= 0 && needToInsert < a[j]; j -= h)3 ;#endif
特性
该算法的优点是可以处理大规模的数据,适用于大部分场合,其它更复杂优秀的排序算法最多比该算法快2倍。缺点是无法处理超大规模的数据
性能分析
使用该算法对n个元素进行排序时
时间复杂度目前在数学上是未知的
空间复杂度为0
归并排序
稳定排序
排序效率与输入无关
归并效果
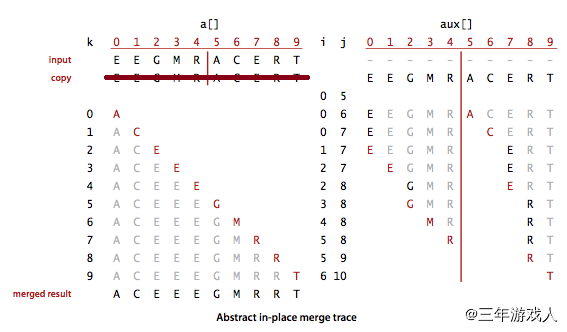
归并过程中的数据变化
自顶向下的排序过程中的数据变化
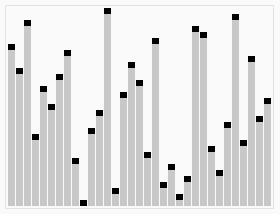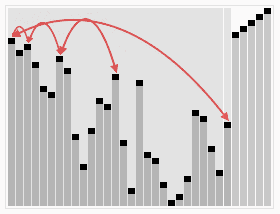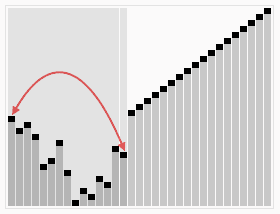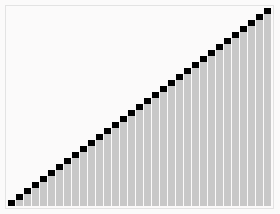
自顶向下的排序过程图形化
自底向上的排序过程中的数据变化
自底向上的排序过程图形化
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 #ifndef __MERGESORT_H__ #define __MERGESORT_H__ #include <iostream> #include <algorithm> using namespace std;class Merge private :char *aux;public :Merge (){ aux = NULL ; }void merge (char *a, int left, int mid, int right) {for (int i = left; i <= right; ++i)int idxOfLeft = left;int idxOfRight = mid + 1 ;for (int i = left; i <= right; ++i)if (idxOfLeft > mid&&idxOfRight <= right)else if (idxOfLeft <= mid&&idxOfRight > right)else if (aux[idxOfLeft] < aux[idxOfRight])else void SortCore (char *a, int left, int right) {if (left >= right) return ;else int mid = (left + right) / 2 ;SortCore (a, left, mid);SortCore (a, mid + 1 , right);merge (a, left, mid, right); void Sort (char *a, int length) {if (aux != NULL )delete [] aux;NULL ;new char [length];SortCore (a, 0 , length - 1 );class MergeBu private :char *aux;public :MergeBu (){ aux = NULL ; }void merge (char *a, int left, int mid, int right) {for (int i = left; i <= right; ++i)int idxOfLeft = left;int idxOfRight = mid + 1 ;for (int i = left; i <= right; ++i)if (idxOfLeft > mid&&idxOfRight <= right)else if (idxOfLeft <= mid&&idxOfRight > right)else if (aux[idxOfLeft] < aux[idxOfRight])else void Sort (char *a, int length) {if (aux)delete [] aux;NULL ;new char [length];for (int subArraySize = 1 ; subArraySize < length; subArraySize <<= 1 )for (int left = 0 ; left + subArraySize < length; left += (subArraySize << 1 )) merge (a, left, left + subArraySize - 1 , min (left + (subArraySize << 1 ) - 1 , length - 1 ));#endif
特性
该算法的优点是能够处理超大规模的数据,缺点是需要O(n)大小的辅助空间
性能分析
使用该算法对n个元素进行排序时
时间复杂度为O(nlgn),元素间的比较次数在最坏的情况下为nlgn次,在最好的情况下为(nlgn/2)次,平均为(nlgn)(3/4)次。
空间复杂度为O(n)+递归辅助栈大小
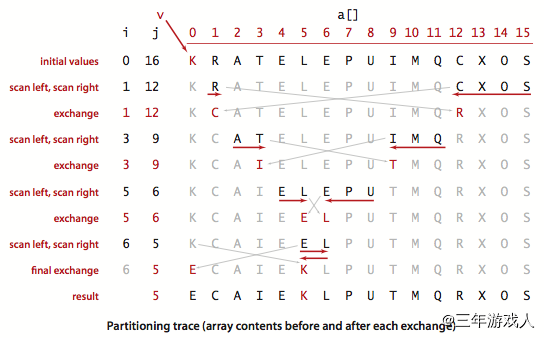
快速排序
非稳定排序
在介绍算法之前需要先了解一个操作--切分
切分的目标是通过调整数组将首元素(或尾元素)放到正确的位置。该位置左边的元素都小于该位置的元素,右边的元素都大于该位置的元素。切分的一个经典应用是查找数组中第k大的元素。需要注意的是,切分要在一个数组上进行各种交换操作,如果不想改变原数组的话,则需要多创建一个数组来进行辅助
快速排序函数的基本步骤:对数组进行切分,再对经过切分得到的两个子数组分别调用快速排序函数
切分效果
切分过程中的数据变化
排序过程中的数据变化
排序过程图形化(每次都用当前数组中的最后一个元素进行切分)
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 #ifndef __QUICKSORT_H__class QuickSort(char * a , int length ) SortCore(a , 0, length - 1) ;SortCore(char * a , int left , int right ) if (left >= right)else int j = Partition(a , left , right ) ;SortCore(a , left , j - 1) ;SortCore(a , j + 1, right ) ;int Partition(char * a , int left , int right ) char standard = a[left ] ;int i = left+1 ;int j = right;while (true )while (i <= right && a[i ] <= standard){ ++i; } while (j >= left + 1 && standard <= a[j ] ){ --j; } if (i < j)char temp = a[i ] ;[i ] = a[j ] ;[j ] = temp;else [left ] = a[j ] ;[j ] = standard;class Quick3waySort(char * a , int length ) SortCore(a , 0, length - 1) ;SortCore(char * a , int left , int right ) if (left >= right)else if 0 char standard = a[left ] ;int i = left+1 ;int j = right;while (true )while (a[i ] < standard && i <= right){ ++i; }while (standard <= a[j ] && j >= left+1 ){ --j; }if (i < j)char temp = a[i ] ;[i ] = a[j ] ;[j ] = temp;else [left ] = a[j ] ;[j ] = standard;int lessRight = j - 1 ;while (true )while (a[i ] == standard && i <= right){ ++i; }while (standard < a[j ] && j >= lessRight + 2 ){ --j; }if (i < j)char temp = a[i ] ;[i ] = a[j ] ;[j ] = temp;else int equelRight = j;SortCore(a , left , lessRight ) ;SortCore(a , equelRight + 1, right ) ;if 1 char standard = a[left ] ;int lt = left;int i = left + 1 ;int gt = right;while (i <= gt)if (a[i ] < standard)char temp = a[i ] ;[i ] = a[lt ] ;[lt ] = temp;else if (a[i ] == standard)else if (a[i ] > standard)char temp = a[i ] ;[i ] = a[gt ] ;[gt ] = temp;SortCore(a , left , lt - 1) ;SortCore(a , i , right ) ;
特性
该算法的优点是可优化的空间大,经过精心调优的快速排序在大多数情况下都会比其他基于比较的排序算法更快,缺点是如果每次切分选择的元素都不正确,算法运行效率就会大幅度降低。例如第一次选了最小元素,第二次选择了次小元素作基准...,这种情况下时间复杂度就会变成O(n^2),但是这种情况出现的概率比你电脑被雷劈中的概率还要小
性能分析
使用该算法对n个元素进行排序时
时间复杂度为O(nlgn),虽然和归并排序一样,但是比归并要快
空间复杂度为递归辅助栈的大小
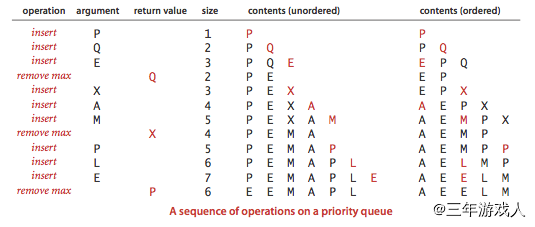
优先队列
在讲解堆排序之前需要先介绍一个数据结构--优先队列。该数据结构每一次取元素都只能获取最大(或最小)的元素
实现优先队列的方式有很多种
可以通过数组来实现无序或有序的优先队列
还可以通过二叉堆来实现。二叉堆是一棵父节点总是大于(或小于)等于两个子节点的二叉树,这样一棵二叉树又可以说是堆有序的。二叉堆可以使用数组形式的完全二叉树来存储
树包括堆,堆包括二叉堆。因为一般使用的堆都是二叉堆,所以通常将二叉堆称为堆
为堆添加或移除元素都会先破坏堆的有序状态,然后再遍历堆来恢复有序状态(这个过程称为堆的有序化)
## 基于二叉堆实现的优先队列 以下二叉堆都是最大堆
上浮过程(插入操作的基础)
下沉过程(删除操作的基础)
插入元素(左)、删除元素(右)的过程
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 //优先队列的一种实现方式:二叉堆// 节点为k,父节点为(k-1 )/2 ,左孩子为2 *k+1 ,右孩子为2 *k+2 int count; // 记录堆中元素的个数int maxN)0 ;delete [] pq;return count == 0 ;int size()return count;q[count] = v;q[0] ;q[0] ;q[0] = pq[count - 1] ;q[count - 1] = temp;0 );return max;int k)while (k > 0 && pq[k] > pq[(k - 1) / 2] )q[k] ;q[k] = pq[(k - 1) / 2] ;q[(k - 1) / 2] = temp;1 ) / 2 ;int k)while (2 * k + 1 < count)int maxChild = 2 * k + 1 ;if (maxChild + 1 < count && pq[maxChild + 1] > pq[maxChild] )if (pq[k] >= pq[maxChild] )break ;else q[k] ;q[k] = pq[maxChild] ;q[maxChild] = temp;
性能分析
基于有序数组的优先队列
N
1
基于无序数组的优先队列
1
N
基于二叉堆的优先队列
lgN
lgN
某种理想的优先队列
1
1
从N个元素中找到最大的M个元素所需的成本:
其他最快的排序算法
NlgN
N
数组实现的优先队列
NM
M
二叉堆实现的优先队列
NlgM
M
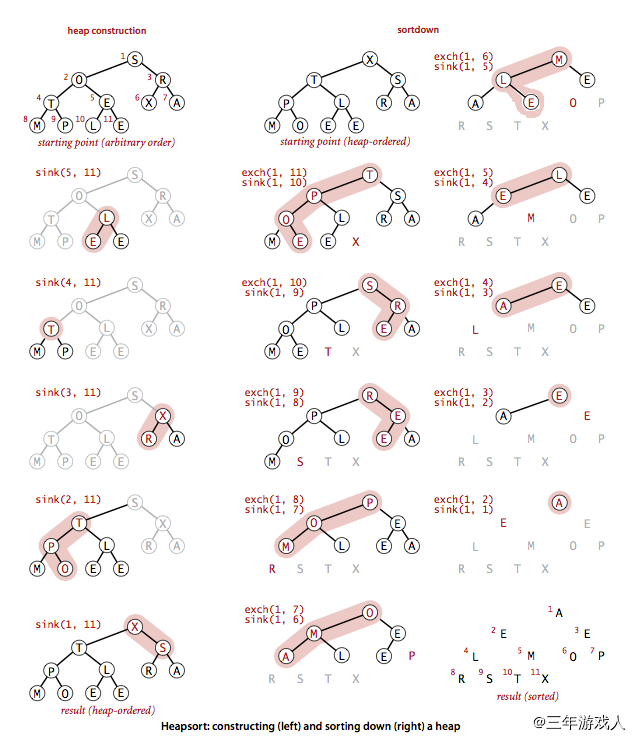
堆排序
非稳定排序
堆排序的基本步骤: 1. 将一个数组建成堆,建堆的方法有两种: 1.
层序遍历二叉树(从左到右遍历数组),每个节点都进行上浮操作 2.
从非叶子节点开始反向层序遍历二叉树(从右到左遍历数组),每个节点都进行下沉操作。这种方式的效率更高,只需要少于2N次比较以及少于N次交换
2. 不断删除堆顶元素
排序过程中的数据变化
排序过程中的数据变化
排序过程图形化
代码实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #ifndef __HEAPSORT_H__ #define __HEAPSORT_H__ class Heap public :void sink(char *a, int k, int count )while (2 * k + 1 < count )int maxChild = 2 * k + 1 ;if (maxChild + 1 < count && a[maxChild + 1 ] > a[maxChild])if (a[k] >= a[maxChild])break ;else char temp = a[k];void sort(char *a,int count )for (int i = (count - 1 ) / 2 ; i >= 0 ; --i)count );for (int i = count - 1 ; i > 0 ; --i)char temp = a[i];0 ];0 ] = temp;0 , i);#endif










.gif)
.png?x-oss-process=style/WaterMask)
.png?x-oss-process=style/WaterMask)
、删除元素(右)的过程.png?x-oss-process=style/WaterMask)